Building a knowledge graph memory system with 10M+ nodes: Architecture, Failures, and Hard-Won Lessons

TL;DR: Building AI memory at 10M nodes taught us hard lessons about query variability, static weights, and latency. Here's what broke and how we're fixing it.
You've built the RAG pipeline. Embeddings are working. Retrieval is fast. Then a user asks: "What did we decide about the API design last month?"
Your system returns nothing or worse, returns the wrong context from a different project.
The problem isn't your vector database. It's that flat embeddings don't understand time, don't track who said what, and can't answer "what changed?"
We learned this the hard way while building CORE a digital brain that remembers like humans do: with context, contradictions, and history.

What We're Building (And Why It's Hard)
At CORE our goal is to build a digital brain that remembers everything a user tells it . Technically it is a memory layer that ingests conversations and documents, extracts facts, and retrieves relevant context when you need it. Simple enough.
But here's what makes memory different from search: facts change over time.
Say you're building an AI assistant and it ingests these two messages, weeks apart:
Oct 1: "John just joined TechCorp as a senior engineer"
Nov 15: "John left TechCorp, he's now at StartupX"Now someone asks: "Where did John work in October?"
A vector database returns both documents, they're both semantically relevant to "John" and "work." You get contradictory information with no way to resolve it.
We needed a system that could:
- Track when facts became true and when they were superseded
- Know which conversation each fact came from
- Answer temporal queries: "What was true on date X?"
This requires two things vectors can't do: relationships and time.

Why a Knowledge Graph With Reification
Knowledge graphs store facts as triples: (John, works_at, TechCorp). That gives us relationships—we know John is connected to TechCorp via employment.
But standard triples are static. If we later store (John, works_at, StartupX), we've lost history. Did John work at both? Did one replace the other? When?
Reification solves this by making each fact a first-class entity with metadata:
Statement_001:
subject: John
predicate: works_at
object: TechCorp
validAt: 2024-10-01
invalidAt: 2024-11-15
source: Episode_42
Statement_002:
subject: John
predicate: works_at
object: StartupX
validAt: 2024-11-15
invalidAt: null
source: Episode_87Now we can query: "Where did John work Oct 10th?" → TechCorp. "How do I know?" → Episode #42.
The tradeoff: 3x more nodes, extra query hops. But for memory that evolves over time, it's non-negotiable.

Three Problems That Only Emerged at Scale
- Query variability: Same question twice, different results
- Static weighting: Optimal search weights depend on query type, but ours are hardcoded
- Latency: 500ms queries became 3-9 seconds at 10M nodes

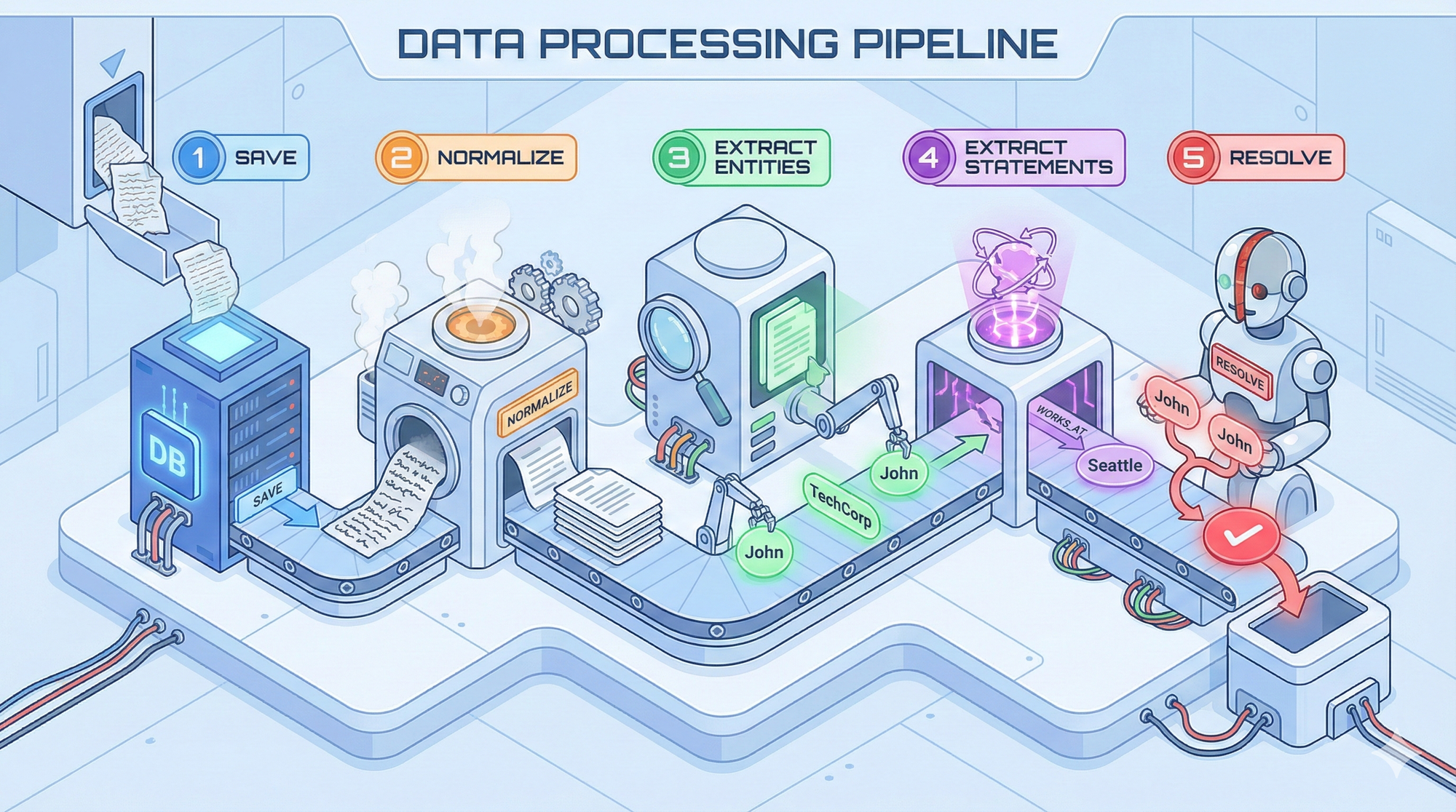
How We Ingest Data
Our pipeline has five stages:
Stage 1: Save First, Process Later
We save episodes immediately before processing. When ingesting large documents, chunk 2 needs to see what chunk 1 created.
Stage 2: Content Normalization
We don't ingest raw text—we normalize using session context (last 5 episodes) and semantic context (5 similar episodes + 10 similar facts). The LLM outputs clean, structured content with timestamps.
Input: "hey john! did u hear about the new company? it's called TechCorp. based in SF."
Output: "As of December 15, 2025, a company named TechCorp exists and is based in San Francisco."
Facts: ["TechCorp is a company", "TechCorp is in San Francisco", "John moved to Seattle"]Stage 3: Entity Extraction
The LLM extracts entities and generates embeddings in parallel. We use type-free entities, types are hints, not constraints—reducing false categorizations.
Stage 4: Statement Extraction
The LLM extracts triples: (John, moved_to, Seattle). Each statement becomes a first-class node with temporal metadata and embeddings.
Stage 5: Async Graph Resolution
Runs 30-120 seconds after ingestion. Three deduplication phases:
- Entity dedup: Exact match → semantic similarity (0.7 threshold) → LLM evaluation only if needed
- Statement dedup: Structural matches, semantic similarity, contradiction detection
- Critical optimization: Sparse LLM output—only return flagged duplicates, not "not a duplicate" for 95% of entities. Massive token savings.
How We Search
Five methods run in parallel, each covers different failure modes:
| Method | Good For | Bad For |
|---|---|---|
| BM25 Fulltext | Exact matches | Paraphrases |
| Vector Similarity | Semantic matches | Multi-hop reasoning |
| Episode Vector | Vague queries | Specific facts |
| BFS Traversal | Relationship chains | Scalability |
| Episode Graph | "Tell me about X" | Complex queries |
BFS Traversal Details:
Extract entities from query (unigrams, bigrams, full query), embed each chunk, find matching entities. Then hop-by-hop: find connected statements, filter by relevance, extract next-level entities. Repeat up to 3 hops. Explore with low threshold (0.3), keep high-quality results (0.65).
Result Merging:
- Episode Graph: 5.0x weight
- BFS traversal: 3.0x weight
- Vector similarity: 1.5x weight
- BM25: 0.2x weight
Plus bonuses: concentration (more matching facts = higher rank), entity match multiplier (50% boost per match).

Where It All Fell Apart
Problem 1: Query Variability
User asks "Tell me about me." The agent might generate:
- Query 1: "User profile, preferences and background" → Detailed recall
- Query 2: "about user" → Brief summary
Same question, different internal query, different results. You can't guarantee consistent LLM output.

Problem 2: Static Weights
Optimal weights depend on query type:
- "What's John's email?" → Episode Graph needs 8.0x (we have 5.0x)
- "How do distributed systems work?" → Vector needs 4.0x (we have 1.5x)
- "TechCorp acquisition date" → BM25 needs 3.0x (we have 0.2x)
Query classification requires an extra LLM call. Wrong classification → wrong weights → bad results.
Problem 3: Latency Explosion
At 10M nodes:
- Entity extraction: 500-800ms
- BM25: 100-300ms
- Vector: 500-1500ms
- BFS traversal: 1000-3000ms
- Total: 3-9 seconds
Root causes:
- No userId index (table scan of 10M nodes)
- Neo4j computes cosine similarity for EVERY statement—no HNSW index
- BFS explosion: 5 entities → 200 statements → 800 entities → 3000 statements
- Memory pressure: 100GB for embeddings on 128GB RAM

The Migration: Separating Vector and Graph
Neo4j is brilliant for graphs. It's terrible for vectors at scale:
- Single-threaded HNSW implementation
- No quantization (1024D vectors = 100GB for 10M nodes)
- Can't scale graph and vector workloads independently
New Architecture:
VectorStore (pgvector)
├─ Semantic similarity, ANN search
└─ HNSW optimized, quantization, horizontal scaling
GraphStore (Neo4j)
├─ Relationship traversal, temporal queries
└─ Cypher queries, provenance tracking
Coordination Layer
├─ Hybrid search orchestration
└─ Entity ID mappingsEarly Results (dev environment, 100K nodes):
- Vector search: 1500ms → 80ms
- Memory: 12GB → 3GB
- Graph queries: unchanged
Production target: 1-2 second p95, down from 6-9 seconds.

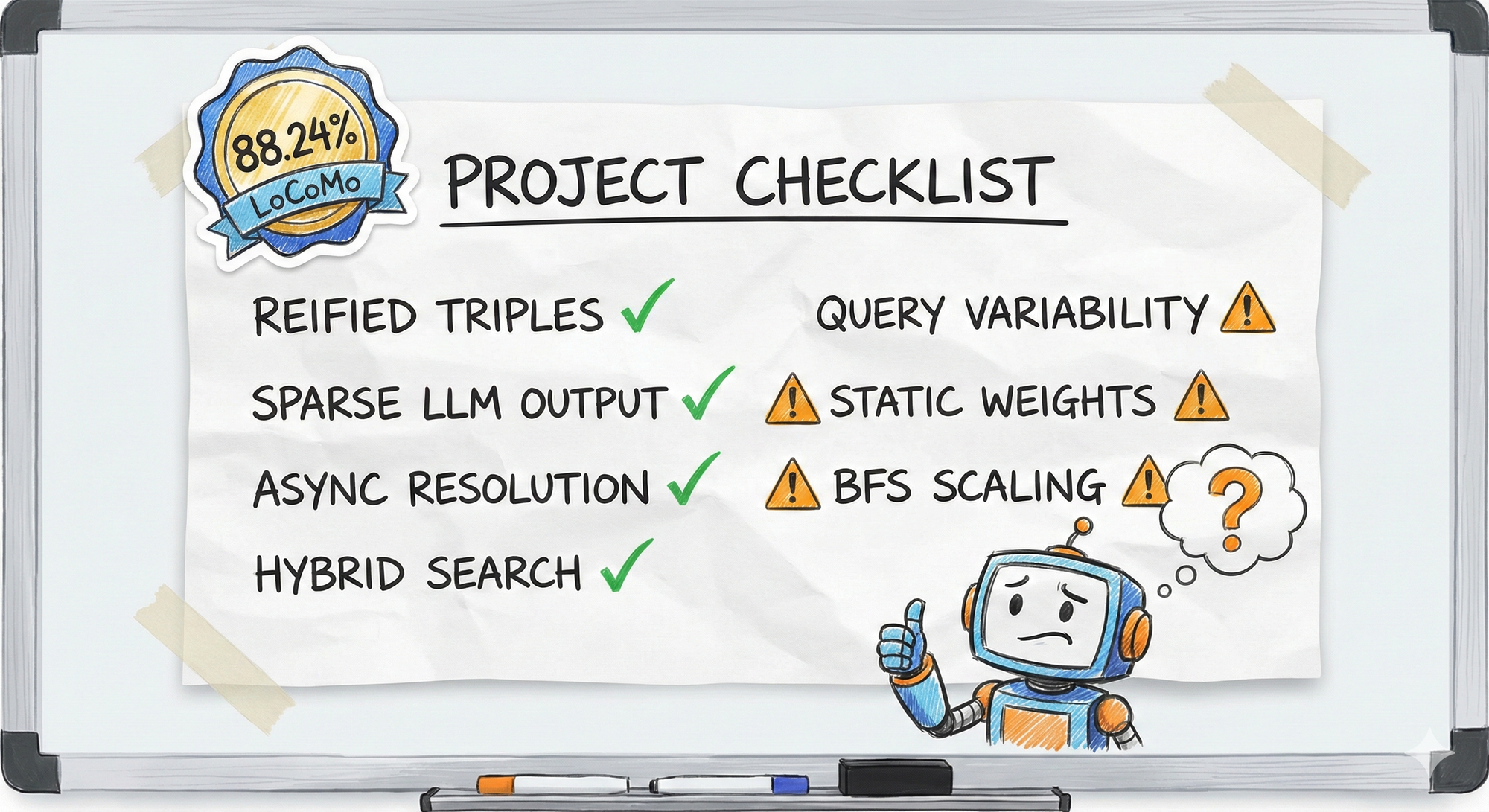
Key Takeaways
What Worked:
- ✅ Reified triples for temporal tracking
- ✅ Sparse LLM output (95% token savings)
- ✅ Async resolution (fast ingestion, background quality)
- ✅ Hybrid search (multiple methods cover different failures)
- ✅ Type-free entities (fewer false categorizations)
What's Still Hard:
- ⚠️ Query variability from LLM-generated search terms
- ⚠️ Static weights that should be query-dependent
- ⚠️ BFS traversal scaling
Validation: 88.24% accuracy on LoCoMo benchmark (long-context memory retrieval) state of the art for AI memory systems.
The Big Lesson
You can't just throw a vector database at memory. You can't just throw a graph database at it either.
Human-like memory requires temporal intelligence, provenance tracking, and hybrid search, each with its own scaling challenges. The promise is simple: remember everything, deduplicate intelligently, retrieve what's relevant. The reality at scale is subtle problems in every layer.

Get Started
- 🔍 Code: github.com/RedPlanetHQ/core
- 🚀 Sign Up: app.getcore.me
- 💬 Community: Discord | Twitter
- 📊 Docs: docs.getcore.me
⭐ Star the repo if this was useful, helps us reach more developers.
