OpenClaw users kept complaining about memory. We fixed it.


I'm the founder of CORE (a digital brain with memory agent + actions for AI Tools). OpenClaw is the most viral AI Assistant and is blowing up - 100k+ stars, 50k+ users in just weeks.
But users kept hitting the same wall: memory doesn't work.
TLDR: Install persistent memory for OpenClaw →
https://github.com/RedPlanetHQ/openclaw-core
I pulled up some complaints from Reddit, GitHub, and HN. Same phrases kept showing up
"It almost feels like it never wants to utilize its memory" - Reddit
"Bot will write stuff down, then later say it never wrote it down" - GitHub
"When you start a new chat you're back to explaining everything from scratch" - HN
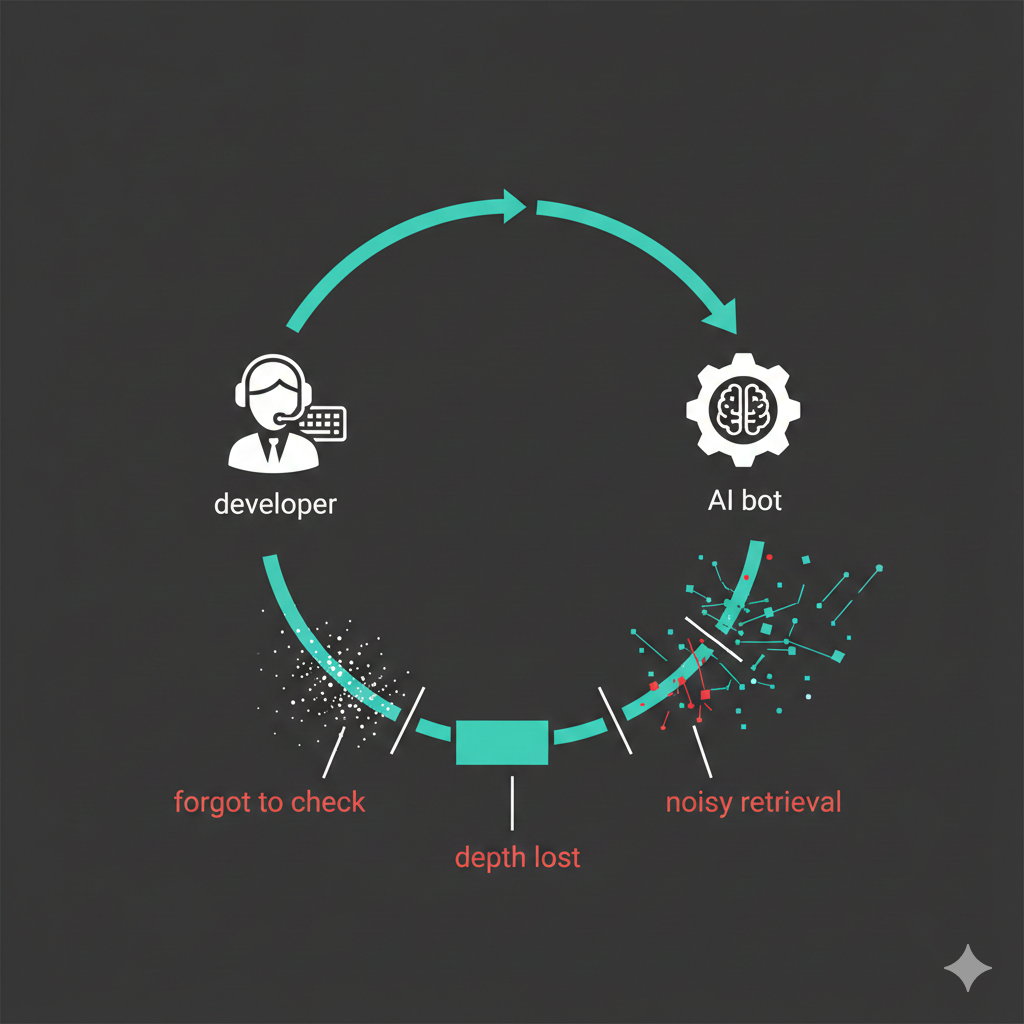
Provide a caption (optional)These aren't edge cases. This is the default experience for most OpenClaw users. And when you dig deep into why that's the case, 3 problems surface:
Problems with OpenClaw Memory
- OpenClaw treats memory as a tool the model can "choose" to use. Problem is, models aren't trained to consistently call tools. They forget. They skip. They ignore context sitting right there. One user put it perfectly: *"Memory needs to be fed into the model on every run, not something it has to remember to check."
- OpenClaw's memory lives in MEMORY.md files loaded into the context window. During long sessions, context gets compressed to save tokens. Even when memories survive compaction, they lose depth. A detailed discussion - why you chose a certain approach, the tradeoffs, the constraints gets flattened into "uses PostgreSQL." The reasoning disappears. Next time you ask why, the agent can't tell you since compaction preserved the fact but stripped the context behind it.
- Memory search has no intelligence it does flat text matching across everything you've ever stored. Working on your frontend? It pulls in notes from an unrelated backend discussion because words overlap. The agent gets 20 loosely related facts when it needed 3. More non-relevant context doesn't make agents smarter, it makes them confused.
So we built a fix - CORE memory plugin
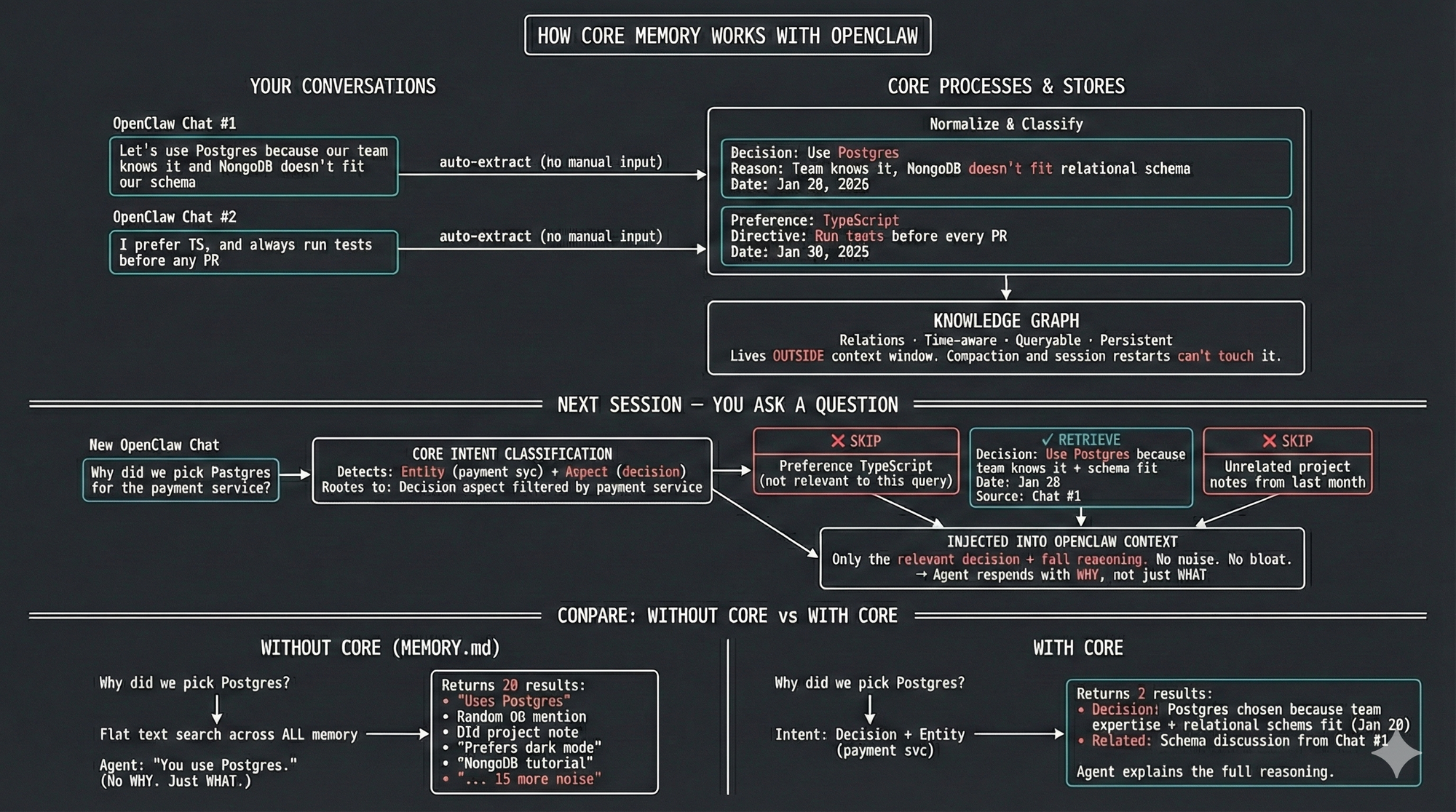
CORE stores memory "outside" the context window in a persistent knowledge graph. Here's what that changes:
Auto-injection
Before each query, CORE searches stored memories and injects relevant context automatically. The model doesn't "choose" to remember, it just has the context.
Normalized event storage
Every conversation goes through a normalization pipeline - each message is linked against your existing context, enriched with timestamps, and stored as a complete episode capturing what happened, when, and why. From that episode, CORE extracts structured facts and classifies each one by Aspect type - was this a preference, a decision, a directive, a relationship? So when you tell your agent "let's go with PostgreSQL because our team already knows it and MongoDB's document model doesn't fit our relational data," CORE doesn't just store "uses PostgreSQL." It captures the full reasoning as a Decision, links it to the project context, and preserves the tradeoffs you considered. Months later, when you or your agent asks why — the answer is still there.
Intent-driven search, not flat retrieval
Most memory systems run a similarity match across everything and dump the closest matches into context. CORE first classifies what you're actually asking for:
- Asking about preferences? → Filters to only Preference facts
- Looking up a person or service? → Traverses entity connections in the graph
- Asking what happened last week? → Filters by time range
- Asking why two things are connected? → Traverses relationship links
So when you ask "what are my coding preferences?" CORE doesn't search across every conversation you've ever had. It recognizes this as a Preference query, filters to statements classified as Preferences, and returns exactly what you need: "Prefers TypeScript," "Uses pnpm," "Avoids class components."And because all of this lives outside the context window, compaction can't touch it. Session restarts don't wipe it. Every fact traces back to the original conversation, so you always know where an answer came from.
Setup
- Install the plugin:
openclaw plugins install @redplanethq/openclaw-corebrain2. Get your CORE API key from https://app.getcore.meConfigure and you're done.
CORE is open source
OpenClaw is the most viral AI assistant in months. But memory is the difference between a tool and a teammate. Agents shouldn't forget what you told them 10 minutes ago.
CORE makes it persistent. Automatic. Actually useful.
🔗 Plugin : https://github.com/RedPlanetHQ/openclaw-core
🧠 CORE: https://github.com/RedPlanetHQ/core
CORE is also open-source. It is built for developers who need agents that remember.
Sources
- Hacker News - https://news.ycombinator.com/item?id=46872465
- Medium - https://medium.com/aimonks/clawdbots-memory-architecture-pre-compaction-flush-the-engineering-reality-behind-never-c8ff84a4a11a,
- X - https://x.com/anitakirkovska/status/2019501743508164991
- GitHub issue - https://github.com/openclaw/openclaw/issues/2910
- Discord - https://www.answeroverflow.com/m/1465582793584017499
- Blog - https://chrislema.com/the-ai-memory-solution-we-all-need-no-its-not-openclaw/